


StorPool is developing a Disaster Recovery Engine (DRE) for Linux-based virtual machines based on site-to-site replication between its storage arrays.
A Linux KVM (kernel-based virtual machine) system has, like VMware, a hypervisor running virtual machines. The VMs are loaded from a storage system and, as they operate, make changes to their stored data. When StorPool provides the external storage array, these changes in the primary system can be replicated to a distant, secondary StorPool system. Should the primary system fail for any reason, the VMs can be restarted at the secondary site and use the replicated data.
StorPool says this type of VM-based data replication for disaster recovery is common in the VMware environment, blogging: “There is no KVM-equivalent for their disaster recovery, VMware Live Site Recovery (VLSR), formerly known as VMware Site Recovery Manager (SRM).” There is no such cross-site intelligence in the KVM area, meaning that any DR arrangement has to be provided by a third party or self-created and managed. The first alternative can be costly and the second difficult and needing ongoing maintenance.
The StorPool blog says: “With StorPool Disaster Recovery engine – a built-in component of the StorPool Storage solution – organizations can configure policies for data replication to remote sites and automate failover (and failback) between sites.”
StorPool comes as a Fully Managed Service/Storage-as-a-Service (STaaS) offering and DRE is integrated with StorPool’s existing licensing. StorPool clusters and systems at multiple sites can be managed from a single console, through cloud orchestration tools such as CloudStack, OpenNebula, OpenStack, or Proxmox. The company says many of its service provider customers build their own management tools using StorPool’s RESTful APIs.
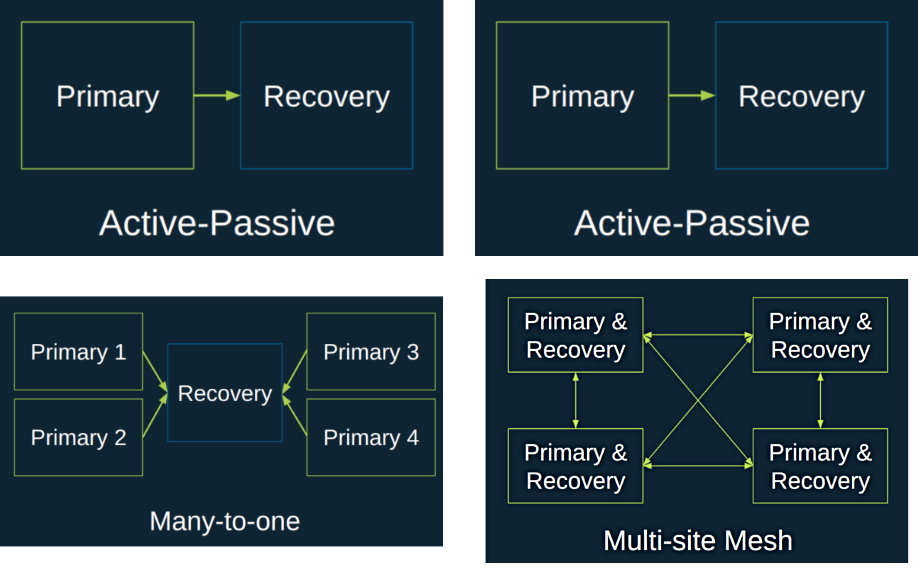
The replication be active-passive and 1-to-1, with an active primary site replicating data and VM recovery points to a passive secondary site. Failover is automated but not automatic; a person has to initiate the switchover.
There is a 1-to-1, bi-directional, active-active alternative between two datacenters, with each site replicating to the other. Should one site fail, the remaining single site starts the remote site’s replicated VMs and runs both workloads.
A less expensive many-to-1 DR option is to have several active primary sites replicating to a single secondary site, probably in a different geographic region. The thinking is that a disaster would likely strike one site only and the risk of two or more sites being simultaneously hit is extremely unlikely.

A further alternative is to have a multi-site, active-active system have each site replicating some of its VMs to one target site and others to a different site in a multi-site mesh. The blog says this allows load-balancing across multiple sites. ”You can think of it as a combination of multiple pairs of bi-directional sites configured into a larger solution.” StorPool suggests: “This model can be ideal for customers running and supporting multi-region clouds.”
RapidCompute is a web hosting business in Karachi, Pakistan. CTO Imtiaz Khan stated: “StorPool’s Disaster Recovery (DR) Engine has become a pivotal component of RapidCompute’s offerings, enabling us to integrate advanced DRaaS capabilities into our KVM-based OpenStack cloud platform.” It can “consistently meet stringent RPO and RTO objectives.”
StorPool’s Disaster Recovery Engine can protect environments with tens to thousands of VMs. It is now in public beta, with general availability scheduled for Q2 2025.





