


Both WEKA and VAST Data aim to solve the problem of AI inferencing context history overflowing GPU memory and slowing down large language model (LLM) responsiveness.
VAST Data co-founder Jeff Denworth writes: “As a chat or agentic AI session grows in length across multiple prompts and responses, the history that is created is known as context. Context is created and stored using self-attention mechanisms that store session history as a series of vectorized tokens (stored as keys and values) that consume considerable amounts of GPU and CPU memory, often leveraging key-value caches.”

WEKA co-founder and chief architect Maor Ben-Dayan writes: “A fundamental limitation in modern AI inference is the amount of memory available – GPUs process vast amounts of data in parallel, but the memory available per GPU is fixed. As models grow in complexity and require longer contexts, their memory footprint expands beyond what a single GPU can handle. This results in inefficiencies where GPUs are memory-starved, causing significant bottlenecks in token generation. This is a particular challenge during the decode phase of Large Language Models (LLMs), which are memory-bound, requiring fast data retrieval to process input prompts efficiently.”
He adds: “One of the biggest challenges emerging in inference is the impact of expanding context lengths on compute requirements. As techniques like reasoning tokens increase, models must process significantly longer sequences, putting additional strain on memory and compute resources.”
Both companies aim to fix this issue by giving GPUs access to the context they need, each in its own way. WEKA does it by speeding up token load time and VAST by being picky about which tokens to load first.
WEKA tested the Llama3.170B model and found that it took about 24 seconds to load a 100,000-token prompt into a key-value (KV) cache in a prefill phase to initialize the model before any output was generated. It sought to load and apply the cache at scale, demonstrating how “extending GPU memory to ultra-fast storage can dramatically improve token processing efficiency.”
The ultra-fast storage was an eight-node WEKApod with PCIe Gen 5 connectivity linked to an Nvidia DGX H100 server via Nvidia’s Quantum-2 QM9700 64-port 400 Gbps InfiniBand switches.
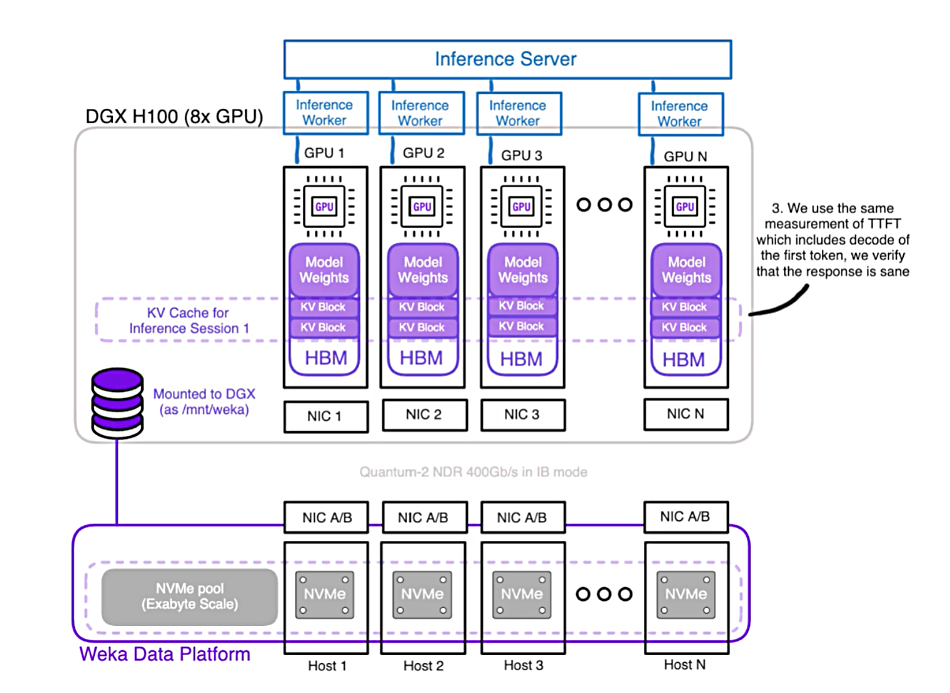
Ben-Dayan says WEKA did its testing with no KV cache compression or quantization – a compression method based on mapping high-precision values to low-precision ones. It reduced the prefill time from 23.97 seconds to 0.58 seconds, a 41x reduction. He says: “Of the 0.58 seconds, the data transfer time was less than 0.2s, so this has the potential to be reduced even more by reducing the overhead of the inference session in the engine.”
He noted: “We also see huge prefill time improvements with much smaller context sizes, even with context lengths as small as 50 tokens.”

The use of the WEKApod provides a “fast resume of inference jobs.” WEKA’s software already “has the capability to align reads and writes into GPU memory (via GDS) directly to the NIC closest to the GPU, and extract every last bit of performance by reducing unnecessary data movement and latency.” The WEKApod is the icing on this cake.

VAST Data takes a different tack, with a so-called undivided attention scheme. Denworth notes: “As context length grows, machine memory consumption scales linearly. Long-sequence chat or agentic sessions can put pressure on system resources and cause memory overflow.
“Cache space is limited to what can be held in a GPU machine. AI services with multiple tenants (that periodically sign in and out of AI applications) need to constantly evict non-active session data from GPU and CPU cache to make room for whatever is happening at the moment.”
Reloading the cache from public cloud object storage “is so long that several leading AI-as-a-service shops choose to simply recalculate an entire prompt history rather than grab all of the context and attention data from object storage.” VAST wants to make “scalable, multi-tenant inference fast, more cost-efficient and global.”
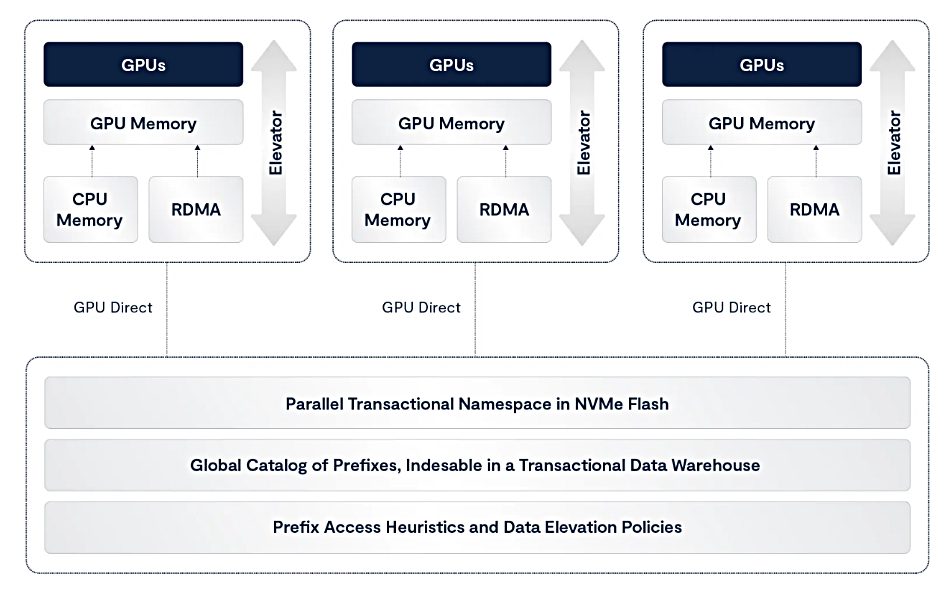
It has developed “a Linux-based agent that runs in your GPU servers and provides a new data presentation layer to AI frameworks.” This is the VUA agent, VAST Undivided Attention. Each GPU server’s VUA is hooked up to a shared VAST RDMA-attached NVMe storage system.
When tokens are not found in GPU Server’s KV cache, they are reloaded from the VAST storage via the GPUDirect protocol providing what Denworth calls “an infinite memory space for context data.”
VUA has “the ability to intelligently store and serve prefixes,” with prefixes being the initial token sequence need to provide the model’s context.
According to Denworth: “Each token in a sequence attends to all previous tokens via self-attention, producing key and value vectors for every position. During tasks like text generation, the model processes one token at a time after an initial input (the prompt) … The KV cache stores these vectors for all tokens processed so far, so the model only computes keys and values for the new token and retrieves the rest from the cache.”
VUA can load prefixes by priority and policy so that, for example, “the longest prefixes associated with a sequence can be served first to a GPU machine,” getting the session underway faster. He says: “Prefixes can also be stored to help multiple related prompts share similar context within a GPU machine,” thus reducing the number of cache misses and reloads from the VAST storage.
Because of VAST’s V-Tree search technique, a VUA can “search through prefixes in constant time regardless of the size of the vector space.” This vector space can scale out to billions and trillions of prefixes. We’re told: “Each GPU server now has shared access to the same extended context cache space, the same rapidly-searchable metadata space and the same global context and attention data and data index.” A preliminary VUA version is being rolled out to VAST’s model builder customers.
Both the VAST storage system and WEKAPod supply fast token feeding to the GPU servers. WEKA has optimized KV cache loads times by extending GPU memory to include the WEKApod, achieving up to a 41x speedup – though details on the comparison system are not provided.
VAST has also extended GPU memory and optimized KV cache load times by applying intelligence to selecting which prefixes to load that get the model running faster and reducing KV cache misses.





