


Analysis: The Alletra MP X10000 object storage system from HPE is representative of a new class of scale-out storage hardware with a disaggregated shared everything (DASE) architecture pioneered by VAST Data. Dimitris Krekoukias, a Global Technology and Strategy Architect at HPE, has written a blog cataloging its main features and explaining why they were included in its design.
He lists RDMA and GPUDirect for S3, Data Service Partitions, key-value store underpinnings, single bucket speed, balanced read and write speed for high-throughput and small transactions, small write buffering, and more.
It is built with HPE technology, not OEM’d software or licensed hardware, and is constructed from ProLiant-based storage server controller nodes and separate all-flash storage or capacity nodes, hooked up across an NVMe internal fabric and existing in a global namespace. The containerized OS provides object storage in its initial incarnation, but could support other protocols on top of its base log-structured key-value store. Additional protocol layers could be added.
Krekoukias says: “These protocol layers are optimized for the semantics of a specific protocol, treating each as a first-class citizen. This allows X10000 to take advantage of the strengths of each protocol, without inheriting the downsides of a second protocol or running protocols on top of each other (like Object on top of File or vice versa).”
HPE needed the system to provide fast access to object data using RDMA (remote direct memory access) and Nvidia’s GPUDirect for S3 protocol to provide direct storage drive access to GPU servers. Krekoukias writes: “This technology will both greatly improve performance versus TCP and significantly reduce CPU demands, allowing you to get a lot more out of your infrastructure – and eliminate NAS bottlenecks from GPUDirect pipelines.”
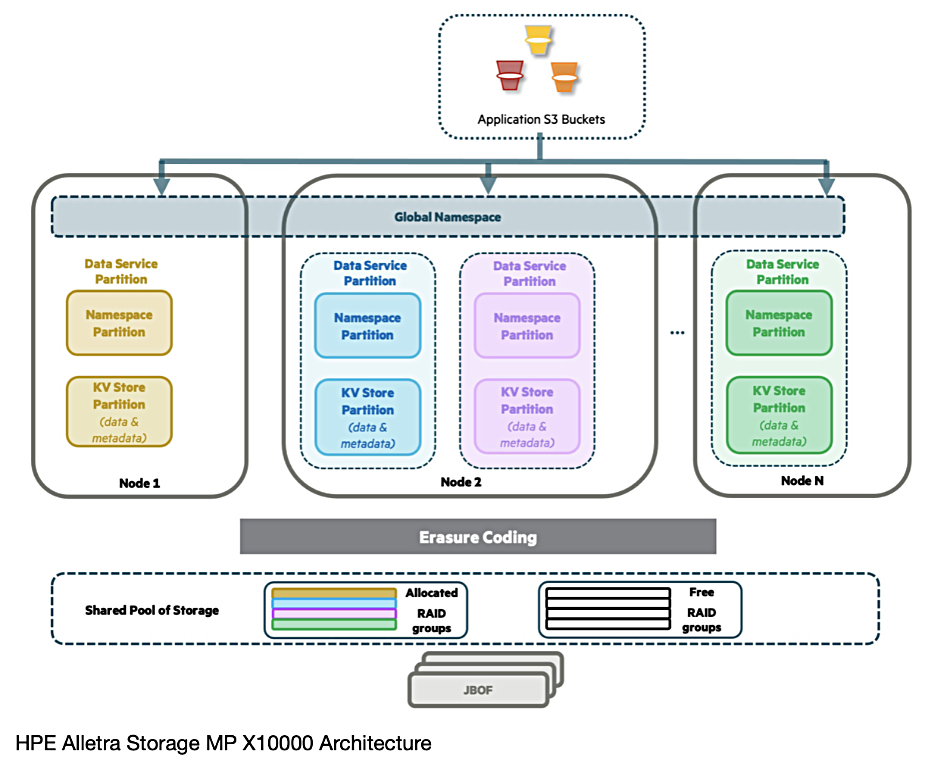
He claims: “Extreme resiliency and data integrity are ensured with Triple+ Erasure Coding and Cascade Multistage Checksums (an evolution of the protection first seen in Nimble and then Alletra 5000 and 6000).” The write buffer is in the SSDs and not NVRAM, “eliminating the HA pair restriction.” There’s more about this here.
Each drive is partitioned into so-called small logical drives or disklets, as small as 1 GB, which are put in RAID groups. These can be confined to a JBOF (storage node) or span JBOFs to protect against failure. Incoming data is compressed and “good space efficiency is ensured by using 24-disklet RAID groups.”
Workloads are sliced up into Data Service Partitions (DSPs) and the DSP shards run on separate controller nodes. If one or more controller nodes are lost, the affected DSPs “just get nicely and evenly redistributed among the remaining controllers.” Disklet RAID slices are dynamically allocated to DSPs as needed.
Krekoukias points out: “Because all state is only persisted within JBOFs and nodes are completely stateless, this movement of DSPs takes a few seconds and there is no data movement involved … Since objects are distributed across DSPs based on a hash, performance is always load-balanced across the nodes of a cluster.” Compute and storage capacity can be scaled independently.
Apart from GPUDirect for S3, performance has been a huge focus in the system’s design. The blog tells us that “typical unstructured workloads such as analytics and data protection assume a single bucket or a small number of buckets per application unit such as a single warehouse or backup chain.” There is no need to have multiple small buckets to improve I/O performance because of the DSP shards concept.
He writes: “X10000’s ability to scale a single bucket linearly means individual applications benefit from X10000’s scale out ability just the same as a large number of applications or tenants.”
The X10000 has balanced performance, HPE says, as it “is designed to provide balanced read vs write performance, both for high throughput and small transactional operations. This means that for heavy write workloads, one does not need a massive cluster. This results in an optimized performance experience regardless of workload and provides the ability to reach performance targets without waste.”
The system’s “X10000’s log-structured Key-Value store is extent-based” and extents are variable-sized. An extent is a contiguous block of storage that holds multiple key-value pairs, thereby increasing access speed. Metadata and data accesses can also be adapted to application boundaries.
The “X10000’s write buffer and indexes are optimized for small objects. X10000 implements a write buffer to which a small PUT is first committed, before it is destaged to a log-structured store and metadata updates are merged into to a Fractal Index Tree for efficient updates.”
Small object writes (PUTs) “are committed to X10000’s write buffer prior to destaging them to the log-structured, erasure-code-protected store. The commit to a write buffer reduces the latency of small PUTs and reduces write amplification. The write buffer is stored on the same SSDs as the log-structured store and formed out of a collection of disklets.”
Krekoukias says: “An SSD-based write buffer can deliver the same high reliability and low latency as prior approaches such as NVDIMM, even for latency-sensitive structured data workloads.”
All these design points mean that small X10000 configurations, ones with only 192 TB of raw capacity and 3.84 TB SSDs, can get good performance and it is not necessary to scale up the cluster to achieve high performance.





